Breaking down addresses to build up our search: how we created a lightweight, multilingual address parser to improve search quality
Building a geocoder isn't easy. Addresses are complex representations of human geographies encapsulating a location in a concise, hierarchical, and memorable sentence. One person may write an address as `10 Downing Street, London, England, SW1A 2AA`, while another may write `10 Downing St., Westminster, United Kingdom`. They both represent the same physical location but are lexically different. Even when an address contains the same word it may be representing a different concept. For instance in, `10 Oxford Street, London` and `10 Main Road, Oxford, England`, the word Oxford represents the name of the street and the name of a city. This can make searching address data incredibly difficult. At Naurt we know this first hand - we've had plenty of feedback on search results that have incorrectly matched an address like `Flat 3, 7 Wiggly road` to `7 Wiggly Flat, Flat Road`. It's a tricky problem, but in the era of LLMs we set out to see if we could do a better job.
We theorised that the key to improving our address search was effective address parsing. Address parsing is where an address written as one sentence, `10 Downing Street, London, England, SW1A 2AA` is split up into its constituent parts:
1{
2 "street_number": 10,
3 "street_name": "Downing Street",
4 "city": "London",
5 "country": "England",
6 "postalcode": "SW1A 2AA"
7}This seemed to us the obvious way forward as we'd previously relied upon text matching and postalcode filtering to match addresses. We did this with Elasticsearch and it worked well for a while as it allows for synonyms (matching Av. to Ave and Avenue for instance), setting requirements on the minimum number of matching phrases, and generally handles large amounts of data with very low latency. However, it knows nothing on the structure of the address - leading to the word Oxford from the previous example having the same search relevancy whether it's the city name or the street name. This problem is exacerbated further in the US where streets are often numbered, leading to searches along the lines of `10 10th Avenue, New York`, or worse still `10 10 Avenue New York`. All Elasticsearch can do is calculate the relevancy and hope for the best! Our first stop was existing open-source projects and we found a few options including libpostal and deepparse. Each parser handles basic addresses extremely well but we found that when it came to complex addresses such as `Flat 1, la ronde court, Trinity Trees, Eastbourne, UK`, they struggled. In this case it might even take a human a few seconds to classify the parts of this address, but there's no real reason why an address parser shouldn't be able to. We therefore decided to make our own address parser and mould it to our own address structure:
With only 10 different classes, this address structure keeps classification simple. It may not be the optimal structure for every country's address, but that doesn't matter much for our use-case. As long as we train our address parser on data classified in the same way we store it, we'll be able to effectively retrieve it from the database.
The hard part of any machine learning or AI project is building a training dataset. Luckily for us address data is usually stored and provided in a structured state. All we needed to do was take different datasets from around the world and standardise them into our format. We then moved on to sampling this data as it wouldn't be feasible to show the parser the entire dataset. We took one random address from every unique street and postalcode combination enabling the parser to see at least one address from every village, town, and city we had data for. We also made sure to include as many unique unit and housenames as possible to ensure the parser saw as much variety as possible in these fields; even "faking" this data in regions where we had none. For each country we included a long list of "other" classified data. Examples of this data include ceremonial counties in the UK or states in Italy. They're generally considered not necessary to the address and not stored in our database, but often show up in user searches. Once we had this sample data we went about varying it. This included removing random postalcodes, administrate areas, and street numbers so that there were large amounts of partial addresses in the training dataset. We then segmented it into a test-train split so we could evaluate the model on unseen data.
The resultant model was under 100mb in size. This is far smaller than similar projects with Libpostal clocking in at around 2GB. Admittedly, the Naurt model only handles around 5 different languages currently but they will grow in number without making much of an impact on model size. The following results have been split into two sections - raw parser performance and the impact it's had on a sample of search data. All results here are based on the unseen test data, it accounts for around 1% of the data we created.
We first computed the Precision, Recall, and F1 scores for the predictions in each label. Precision tells us how often we're right when we've predicted a label and recall tells us how well we've done in finding all of the instances of a specific label. Generally if precision is high and recall is low for a label, the model is missing some things it should be classifying as that label. The F1 is then essentially the mean of those two metrics.
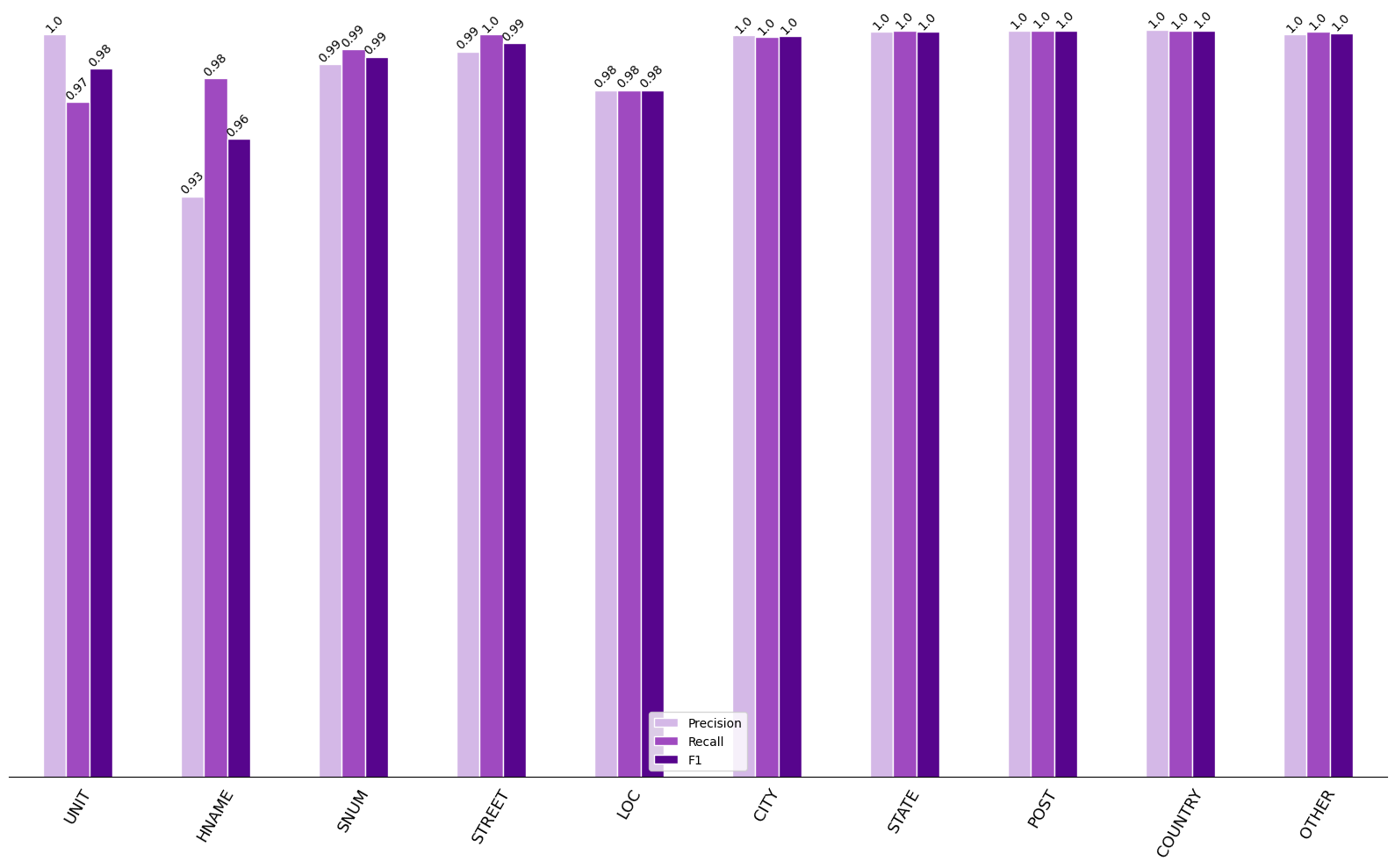
Overall the model performed very well. F1 scores for every category are above 95%. To 2 decimal places, the F1 score is 100% for 5 of the 10 classifications. It's not surprising that the worst category of classification was the housename. This field has by far the most variation and often has no common suffix of type designator. In street names and often in unit names, more often than not there'll be a suffix or prefix denoting what it is. E.g., `Close`, `Avenue`, `Flat`, `Apartment`. As recall is higher than precision in this category we can assume that the model is classifying too many address components as a housename. We can make the assumption that these are actually labelled as units as the results show the opposite for that field. Inspecting the training data shows that often housename and unit are interchangeable. You'll get Flats and Apartments labelled under housename. Again, this is fine as when it comes to implemented a search based on the address parser there's not much harm in searching both fields when something is classified as a unit or a housename. To better understand what is happening in the classification, we can create a confusion matrix. This plots the model's recall and shows us what the true labels were versus what the predicted labels were.

Looking at housename first we can see that in 1% of cases the housename is actually classified as a unit. In the other 1% of incorrect cases it is classified as a street. This has a likely explanation in similarities between housenames and street names. A block of flats often has the suffix court, while the same can be true of a street name for instance. The other place where the parser has a weakness is deciding between locality and city. This is not an issue really as they can be interchangeable within the dataset too. When implementing search, we can make sure both fields are searched. Street number and street is another interesting but understandable case. Streets in North America are often numbered, e.g., 4th Ave, 34th Street. Sometimes these streets are not stored with their ordinal suffix (th) and can therefore become very similar to a street number. When you throw unit numbers into the mix too, it's easy to see how these categories can be incorrectly classified. At this point it's worth noting that the data the model has been evaluated on here comes from the same dataset as the training model. While unseen, it doesn't contain all of the quirks of user inputted data and is therefore considerably cleaner than the data we'd likely get inputted via our search.
To test the quality of Naurt's search with the parser, we first needed to implement a new way to search with the broken down address. We devised a simple method that searches for each component of the address allowing for matching across components in the case of housename and unit, and locality and city. We then boosted the relevancy of certain fields that are important to an accurate search, such as street name and street number. To test how well this search style worked, we ran 20 thousand "difficult" addresses in the US through the Naurt geocoder. The difficult addresses are generally complex, can sometimes have address components repeated, just be plain wrong, and in some cases have incorrect locations due to lack of manual verification. A lot of the time this means the address is not present in the Naurt database and the ideal behavior is to not return a result. We've found that having someone manually check a location is far better than sending them to the wrong location! After getting a result from the geocoder we calculated a distance between the location attached to the difficult address and the location Naurt responded with.

Above is the distribution of the results. There is a clear decrease in the number of results returned by the Naurt search when using the parser. It is also clear that the vast majority of these came from search results that were likely erroneous as the distance between the two locations was over 100m. The reduction in median distance confirms that the parser has been an imrpovement to the search - a great result! Before pushing the model to production, we have one more thing to worry about: response time. On top of request processing and searching our database, we now have extra time being spent on parsing the address. Luckily enough the parser takes a few milliseconds to parse an address when running on the CPU and is therefore used within every request to our forward geocoding endpoint.
Creating and implementing an address parser is not an easy task. Gigabytes of well structured training data with plenty of variation are required to ensure the parser can generalise well enough. The way one address is written and stored in a database may be extremely different from the way a user searches it making a well generalised parser essential. The results we've shown here from Naurt's first implementation of an address parser have substantially improved geocoding search results - mainly by eliminating poor matches that previously would have been returned to users. As Naurt expands into more countries, the parser will be trained on more data in more languages continuing to make it more robust. If you'd like to find out more or ask any questions, please don't hesitate to contact the Naurt team at sales@naurt.com.
Sign up at Naurt for product updates, and stay in the loop!


